
It’s summertime and you decide to make yourself some refreshing homemade ice cream. What would your starting point be?
- Manufacturing a freezer? Cold …
- Farming cocoa and vanilla? Colder …
- Grabbing the right ingredients, mixing them, and using the existing tools to turn them into ice cream? Warmer!
Making ice cream belongs to the class of problems where Cold-Start is a challenge. That has nothing to do with the temperature of ice cream, it refers to the situation where you have to start from scratch: no ready-to-use ingredients, no prior experience. The only way to tackle such tasks is to rely on rich pre-packaged knowledge with high built-in confidence. That is referred to as transferred knowledge with a high signal-to-noise ratio.
The main motivation of this blog post is to give an idea of how Cold-Start can be addressed when solving real-life marketing problems. But before diving into technical aspects, let us frame this as a machine learning problem:
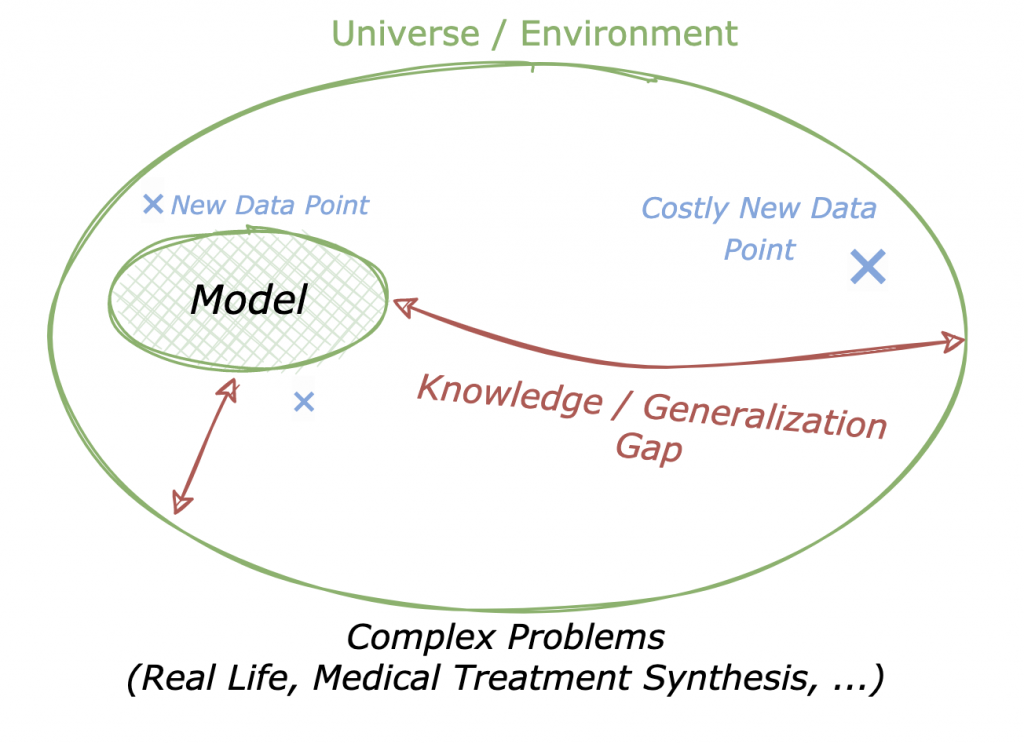
Illustration of real-life through simplified ML lens
Conceptually, you interact with a complex Universe, in which you navigate using a Model. This model comes from all the gathered experience from the environment — both acquired and innate. Yet, the complexity of the interaction with the Universe lies in what can be called the Generalization Gap. Within this area of “unknown” scenarios, you can acquire experience and enrich your model using new data points — some may be costlier than others. Using the ML lens, essentially two terms compose the Generalization Gap: bias and variance. The former captures how close on average your model is from the “truth”, which you rarely have access to, except through observations. The latter refers to the noisy nature of the observation process.
If you are more comfortable with transfer learning frameworks using neural networks, here is an interesting way to see it:
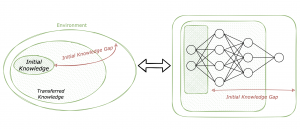
Drawing the parallel between the interaction of the universe and transfer learning for neural networks. The density of each zone reflects the availability of data points.
The first layers of your neural network capture low-level features. They can be learned on a general task involving an extensive amount of data that can be easily retrieved. Denser zones in the drawing indicate that data is more available to acquire initial knowledge. However, in order to embed abstract concepts into your model, the core layers should capture richer high-level features learned on more complex tasks. These core zones of the Environment are less dense because acquiring data points is costlier and you still need a non-negligible quantity to learn robustly. The latter layers can be fine-tuned to adapt to a specific task. For the Cold-Start case where there is not enough data to learn the core features — and that is the case in real-life marketing problems — transferring pre-packaged knowledge is a game-changer.
Therefore, this blog post’s focus is twofold:
- Explain why tackling Cold-Start is critical for real-life marketing problems as opposed to common recommendation applications
- See how this difference manifests in the recommender systems literature in terms of evaluation methodology; in contrast with more advanced fields on the matter such as Natural Language Processing
Criticality of Cold-Start for Real-Life Marketing Problems
Marketing communications of large B2C companies with their customer base require a sizeable effort and can be overwhelming. That is because only 10% of CRM messages can be based on customer behavior while about 90% stem from commercial goals. Traditional personalization techniques work well in the scenario of an existing customer context (10% of CRM messages) but break down for commercial-driven goals (90% of CRM messages.)
Real Marketing is marketing to customers in the absence of a context.
This is the problem we’re solving at Tinyclues. From a technical perspective, we apply Deep Learning to predict buying intent for each product and offer. Concrete applications are various and include promoting new collections, communicating with less active or new customers, etc. These applications share a key concept, they deal with generating new demand which is way costlier in its execution than retargeting or product recommendation. And this is actually where the importance of Cold-Start lies, let’s represent it in our sketch:
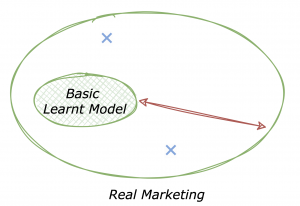
You should not see a major difference with the first “Complex Problems” sketch. Indeed, interacting with real-life marketing problems is very complicated. The slight difference here is that the model shown learned from data by solving a specific task such as purchase prediction. The blue data points show that exploring new horizons in this universe can be costly: efforts for creating new campaigns, acquiring customers, making sense of heterogeneous data sources, etc. Finally, Cold-Start is mainly responsible for the Generalization Gap as it can cause your model to be both biased and suffer from high variance. That is, inference performed by the model can be erroneous and noisy because of the lack of observable behavior from more than 90% of the client’s customer base.
By now it should be clear that new demand generation is tightly linked to Cold-Start and that is the main reason real-life marketing is hard.
And yet, you might find this statement paradoxical:
Cold-Start is a well-identified top challenge in the recommender systems literature, and yet efforts to tackle it have always proved insufficient for real-life marketing use-cases.
Our best guess as to why this disconnect exists is due to the nature of business applications recommender systems were mostly used in, that is applications where:
- Cost of exploration is low: widespread recommendation engines are built on top of closed-loop systems, e.g. banners, websites, apps or any other system where user feedback can be quickly and easily collected. Exploration in this setup — getting feedback from/for “cold” users/items — is pretty cheap. As opposed to that, marketing campaigns for demand generation require novel creative effort and can be expensive. In this setup, the cost of exploration is structurally high because bad CRM increases the risk of customer churn, with the underlying loyalty/acquisition tradeoff.
- Weight of “cold” users/items is marginal: In the closed-loop setup, you can ensure to have a marginal amount of “cold” users/items. Therefore, there is no need to make it a central matter of your models. Unfortunately, the majority of B2C companies don’t lay in this setup. Customers visiting their website represent less than 10% of their customer base.
In short, recommender engines focused more on the following setup:
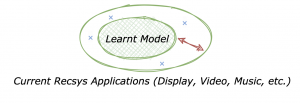
And as they evolve in a closed-loop system, it is easier to “close” the Generalization Gap by performing inexpensive exploration.
Now that you got a sense of why there is a disconnect from real-life marketing in the way Cold-Start is solved in the recommendation field, let’s detail how this manifests in the literature.
Cold Start vs. State of the Art
“Deep Learning achieved State-of-the-art results …” sounds familiar? That is pretty much how most papers started during recent years for many Machine Learning fields. Recommender Systems is no exception — see in Deep Learning based Recommender System survey. What does it mean for our Cold-Start case? In order to understand it, you have to split the affirmation above into two parts.
Let’s start with “State-of-the-art results”. When it comes to evaluating Cold-Start, there is simply no consensus in the protocol within the recommendation field.
The sad truth is that “State-of-the-art results” are obtained in situations where Cold-Start issues are hidden.
The very metrics that are used to benchmark them fade away cold elements by definition, that is class-weighted AUC, log-loss, precision, etc.
Secondly and even worse, some poorly sampled classes are just wiped from the data during the whole process, both in data pre-processing and model evaluation, falling right into the “convenience bias”.
Finally, when papers include Cold-Start in their evaluation process, they tend to consider it at a fixed snapshot, putting aside important time dynamics and almost forgetting that every product was cold at a given time. For instance:
- Products A and B can be poorly sampled but at opposite moments of their life cycles. Product A has just been introduced in the catalog whereas B is being discontinued soon.
- You can rely on other products’ attributes, for example, its brand. However, you have to also take into account the novelty and lifecycle of the brand itself. Furthermore, it is more complex to leverage attributes when catalogs are lacking a hierarchical structure.
These examples encompass product-related concepts such as its lifecycle, its novelty phase, how it appears along with other attributes. All these concepts are central in real-life marketing. Therefore in this setup, not evaluating Cold-Start or reducing it to missing user/product rankings throws you right in the middle of the “streetlight effect”.

In order to avoid the “streetlight effect”, evaluation protocols have to be tailored for Cold-Start
Now moving to the other part of the affirmation: how “Deep Learning” has been used for the modeling part.
In general — even before Deep Learning played a central role in recommender systems — Cold-Start has often been treated as a two-stage independent problem. Modeling approaches have been more focused on solving the collaborative-filtering stage and extending the embeddings using a content-based approach in order to mitigate Cold-Start. Such approaches are not new and are referred to as hybrid. They do not tackle the problem as a whole — good approaches are mentioned in the Recommender systems survey, let’s also cite approaches such as Learning Attribute-to-Feature Mappings for Cold-Start Recommendations and Response Prediction Using Collaborative Filtering with Hierarchies and Side-information, relying on side-information and hierarchical structure respectively. Usually, these two parts are “glued” together using a somewhat rigid ad hoc prior.
Now that usage of deep neural networks is widespread, including in recommender systems, what changed? Focus is still on the collaborative filtering side with more complex models capturing higher-level interactions. Incorporating side-information for Cold-Start was also made much easier by using the great modularity enabled by neural networks architectures. Deep Learning based Recommender System: A Survey and New Perspectives references how deep learning achieved state-of-the-art in recommender systems. Within the many insightful papers cited in the survey, DropoutNet: Addressing Cold Start in Recommender Systems is interesting because the authors go a bit more into details on how tackling Cold-Start can be incorporated in the training. Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings leverages Meta-learning techniques to tackle the challenge of representing a cold item based on categorical side-information. For instance, initializing a new/poorly sampled product_id using its category and brand.
The approaches cited above rely on the great modularity of neural networks but they are still hybrid in essence. Once again, it makes sense to assume the generalization gap is easier to reduce in mainstream applications of recommender systems. However, this induces the following limitation:
The quality of the extended representations is questionable.
On the one hand, their evaluation is not really done. It either consists of projecting them on a 2-D space — generally using PCA or t-SNE — or using them to compute a class-weighted metric that hides Cold-Start. Everyone is aware of the limitations of the former evaluation technique: the 2-D is too simplistic. As for the latter one, the beginning of this section sums it up pretty well.
On the other hand, learning the embeddings in a posterior or in a fully unsupervised fashion leads to a faulty transfer in a complex setup. A simple example to picture it is transferring some item embeddings learned from a user page views task to a user buying task. Features related to the price may be determining in the downstream task but completely squeezed away in the upstream one, leading to a poor transfer.
Therefore, it is natural to look at joint-learning techniques which make Semi/Self-supervised approaches of great interest, especially as they stand on trending frameworks such as Multi-Task or Meta-Learning. In that direction, the most inspiring papers to me include VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain and Self-supervised Learning for Large-scale Item Recommendations which went even further and properly incorporate the impact of characteristic power-law distributions.
How Self-Supervised and Transfer Learning enable a huge leap in NLP

ELMo feeling cold before the popularization of Self-Supervised Learning in NLP
In the exciting papers above, an idea that was trending in recent years in NLP appears: leveraging Self-Supervised Learning. You can have a better grasp of this type of learning through the following Yann LeCun’s presentation at EPFL. Within this concept lies the idea of working with a less “rigid”, more modular, and continuous connection between the upstream and downstream tasks, and that made fields such as NLP achieve a huge leap with BERT or ELMo for example. In other words, it is important to introduce a richer transfer. The question is: how come this transfer approach is more common in NLP (or Computer Vision) than in recommendation? There seems to be at least two elements to answer this question:
- Related to the structure of the data: transfer learning has gained popularity in these fields because of the (almost) universal underlying data structure — In NLP, the language structure: syntax, grammar. In CV: the spatial structure — making it for instance easier to perform data augmentation. Such general structure is not always obvious in the tabular datasets used in recommender systems. Tackling these datasets is also difficult because they contain complex temporal and mostly sparse time series.
- Related to the evaluated tasks: When solving advanced NLP tasks (e.g. question answering), the Cold-Start effect is more observable. Indeed, you rarely see the exact query and the exact answer occurring more than once in the text corpus. Hence, the weight of the long-tailed distribution is more impactful on the final metric (Exact Match — EM and F1 score) as opposed to the setup recommender systems are often used in.
If we would sketch it, it should look something like this:
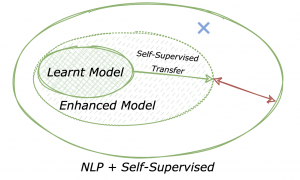
A larger part of the space is covered thanks to transferring rich and meaningful representations, providing a better prior on data distribution that can mitigate the costly data point exploration. And it enabled both performance and robustness enhancements.

ELMo feeling warm after the popularization of Self-Supervised Learning in NLP
Conclusion
Being able to leverage the power of rich latent representations is the secret behind Tinyclues. We have followed this approach in production since 2013. In our experience, this is the best approach to build robust ML systems feeding on real-life first-party customer data and we are very excited to see these ideas gaining more traction in recent years.
Personally, I love Transfer Learning because, if you think about it, the whole story of human civilization — especially in science — is a story of transfer as much as it is a story of learning.
Smart transfer learning is what makes it possible for us to “stand on the shoulders of giants.”
It is a story where major leaps have been achieved because knowledge bottlenecks have been broken and well documented because costlier data points have already been explored and denoised. In brief, it is a story where pre-packaged knowledge with a high signal-to-noise ratio is transferred through time. These knowledge-sharing mechanisms blessed us with ice cream and more generally with amazing technology. They have also enabled huge progress in Machine Learning every day.
Stay tuned
Subscribe to our newsletter – fresh CRM insights and thought-provoking articles delivered straight to your inbox twice a month. Or, see what it looks like here!
By clicking “Sign Up Now”, you agree to our privacy policy



