
Multi-tenant data configuration management can be tricky. What if you treated it the way you treat code?
Tinyclues processes large heterogeneous datasets (first-party customer data from large B2C companies) with advanced machine-learning algorithms (deep learning prediction of customer behavior) to offer a user-friendly SaaS solution where marketers can build and scale intelligent campaign plans.
Thanks to deep learning, we are able to make sense of full first-party customer datasets without any need for data normalization. However, this comes with specific challenges for our data ingestion stack. The data we process is extremely varied:
- industries: retail, travel and even more exotic…
- data structure, which can vary a lot between customers, even within the same industry,
- data quality, depending on the customer’s ability to collect and maintain it.
We cannot rely on industry-standard data-handling frameworks and tools: our challenge isn’t to handle one complex dataset, we need to be able to handle hundreds of complex datasets with a multi-tenant approach and no client-specific code.
Our product must accommodate all these specificities, while remaining generic enough to be able to scale to new customers. This includes things like describing an input schema, describing data transformation at various steps of the value creation chain, describing customer dedicated models and their tuning or specific insights and dashboards we’d like to enable for the client.
A way to achieve this is via customer-specific configuration.
How it started
At the beginning of Tinyclues, with a growing number of clients, our team built an application and a few homemade APIs to satisfy our configuration needs.
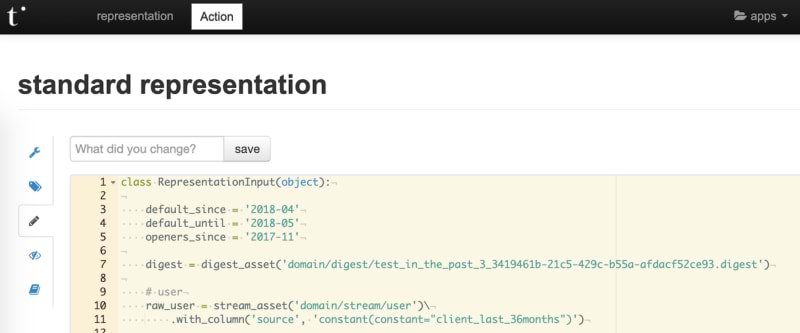
This application allowed internal users (customer success, data scientists and developers) to configure our platform (eg. set up a data integration, tune a predictive model or enable app features) via features like a web editor, ability to tag and diff configuration versions, and even document it.
As we grew, we did start to see some limitations:
- configuration was coded in Python, forcing all users to master the language
- solution offered neither validation nor feedback to user, leading to issues popping at runtime
- inevitable tech debt — app maintenance, code ownership and config management solution commoditization
So we decided to grasp the nettle, but with some lessons learned as a starting point:
- KISS principle and maintainable solution
- ability to seamlessly scale to dozens of customers
- evolution-friendly, especially on how we serve the configuration to apps consuming it
- capitalize on our current tools and skills
And, it has to be said — the old solution also had some features we wanted to keep:
- versioning and diffing
- drafting and manual testing
- autonomy to deploy changes in production
Each problem has its solution
Here’s what we finally came up with:
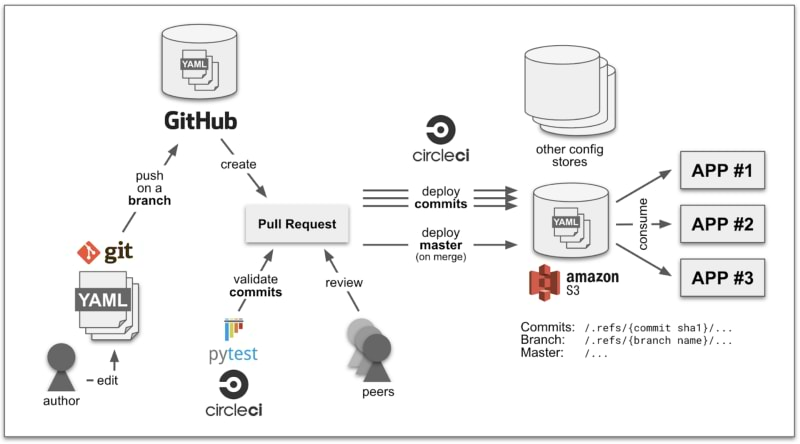
This setup is a mix of technologies, frameworks and workflows.
Please note that any of the tech we mention here (Git, Github, CircleCI, Pytest, S3) can be swapped by an equivalent. We chose these because we were already using them in our projects. You can choose the technology that you and your team are comfortable working with.
Let’s dive into the details.
YAML as the configuration language
YAML is a concise data-serialization language commonly used for configuration files. We chose YAML, first of all, because everyone knows how to edit a text file using a text editor (we like Visual Studio Code). And second of all, compared to its famous alternative JSON, the YAML syntax is both human and diff-friendly.
YAML support is easy in most programming languages. This allows us to generate configuration at scale via scripting and using templates. This comes in very handy when you need to migrate an account or set up a new one.
Another advantage is its compatibility with JSON schema, allowing us to validate any YAML file against a given —potentially complexe— schema. Most text editors use JSON schema to provide auto-complete features and highlight errors.
Finally, mass edit (yeah, sometimes we need to!) is easy via raw plain-text tools like AWK or Sed, or higher-level scripts.
Git as the versioning system
No need to present Git, one of the most popular version-control systems. It is very handy when you want to explain a configuration or diagnose an issue (at least you know who to ask!).
The branching feature allows users to draft on independent parts of the code — here, the business configuration — which is a plus when you need to do many edits on small isolated parts.
We set our master branch as the production configuration. Everything merged on the master becomes the single source of truth.
Github as a collaboration and documentation tool
No need to present Github, either. In addition to hosting, Github also provides powerful features such as Pull Requests. Github, as an authenticated webapp, is also easily accessible by everyone in an organization.
We rely a lot on Pull Requests, because they offer a way to log progress while collaborating with others.The mechanism of review ensures that what is going to be merged has a peer consensus.
The process of release is simple for users: everyone can merge a new configuration or a change. We prefer a squash merge to preserve the master from a high number of non-atomic commits (commit details are logged in the Pull Request anyway).
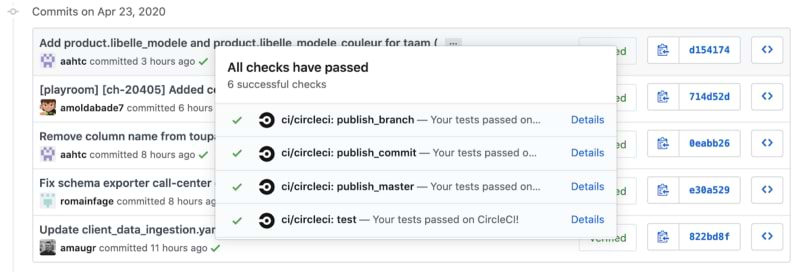
Pytest as the validation framework
Validation feedback needs to be fast, explicit and precise when some checks fail. This is a perfect fit for a unit testing framework. As we are a Python company, pytest was an obvious choice.
Since most changes generally only concern one customer, in order to maintain fast runs, we leverage parametrizing tests and parametrizing fixtures features to only run relevant tests for each commit (eg. only for a given customer). By passing the customer as a pytest parameter (simple to infer from commit diff) and making our tests customer aware, we can maintain fast feedback for users.
Checks we have implemented range from schema validation to cross config file consistency. We even validate some config files against live data! The possibilities are infinite — this is just the beginning of the journey.
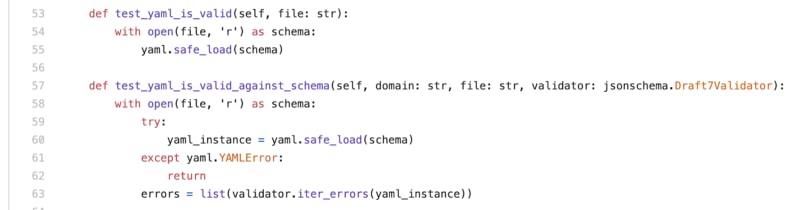
CircleCI as the CI and CD solution
Github Pull Requests are also well integrated with Continuous Integration and Deployment solutions, and offer visual feedback to users. It’s yet another stamp that the Pull Request is ready to be merged or not.
We already use CircleCI on our projects, so plugging it to this one was a no brainer. We just added some workflows that trigger on commit or merge events to run tests and deploy files in the right place.
Funny thing is that the CircleCI recipe is written in…YAML too 😉
S3 as a store to serve the configuration
Amazon S3 is the object storage solution provided by AWS. It allows you to store any kind of object, including business configurations. The main advantage is that S3 provides client SDKs in many languages for free.
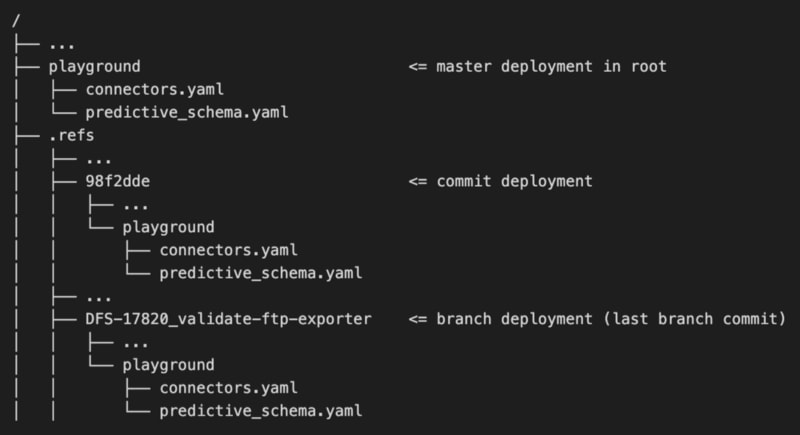
We created a S3 bucket for that purpose, in which we deployed both “production” configurations (the master branch) and “dev” ones (users branches and commits) too, in sub “hidden” directories.
Providing you know the bucket name and the customer and config name you want to fetch, you can find the config. The only thing you need is to give the right IAM permissions.
The “dev” deployments allow users to test their configuration on various systems, just by providing the reference of their branch or commit. However, the system needs to have been built to handle this. We also added a lifecycle rule to automatically purge old deployed commits or branch configurations (we can still redeploy them via our CI).
Cloud File System is a good global choice, but sometimes you need to push your configuration on other stores in order to serve it. Nothing difficult: just hook at deploy time and add an additional sink store.
A real life example
This solution allowed us to enable and accelerate several use cases.
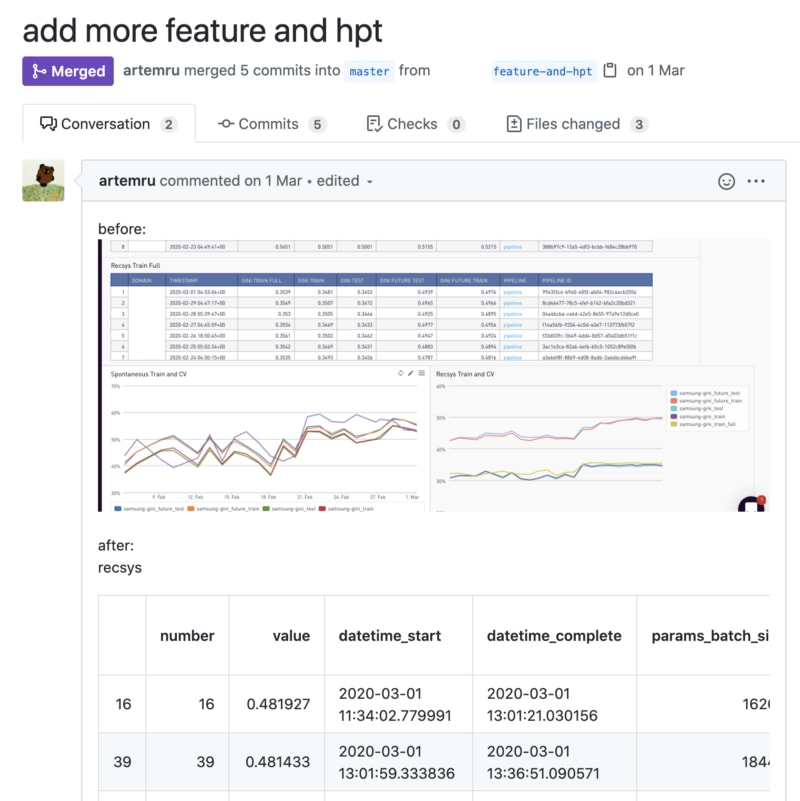
One of them was to provide tuning for our predictive models. This process always needs iterations and discussion amongst data scientists to ensure they perform best.
While tuning the models, results are stored in the Github PR and discussed via comments. Contributors can share graph screenshots, figures, or any other support that justifies the values.
Everything is logged. So if you need to explain a tuning value, you can easily find its author (via the blame feature) and access to the PR that originated it.
Other things to be aware of
The first thing we noted is that an approach like this needs governance, to ensure a consistent configuration and to avoid duplicates. Because adding a new configuration is easy with this setup, such project can grow out of control pretty fast. So every time a team needs to create a new one, we decided it must be approved by at least two peers, including one who regularly edits the configuration for all our customers.
Moreover, any configuration schema evolution requires careful attention. As many systems use the configuration, rollout can be painful. There’s no magic solution here — only planning.
Finally, take care when configuration files start to reference each other: this is by far harder to maintain and part of your validation process needs to check consistency of these files, both ways. Avoid this as much as possible, one source of truth is always better than multiple ones.
Main takeaways
Today, several teams at Tinyclues are using this project (30 contributors, 500+ merged PRs) for many use cases.
We just got a fully functional business configuration edition, versioning and serving in no time. No kidding, the whole stack took less than a week to set up.
Our journey is not finished yet but we’re now comfortable enough with this new approach to foresee a fast and simple future.
